参加レポート
当日の参加レポートを、LeapMind 坂口真里奈 氏に執筆していただきました。(転載元)
機械学習工学研究会キックオフシンポジウムは「業界あるある」と「共感」に満ちていた 〜イベントレポート〜

5/17に開催された、機械学習工学研究会キックオフシンポジウムというイベントに参加してきました!
機械学習特有の課題を見据えながら、既存のソフトウェア工学をベースにしながら今後の機械学習システムの開発・運用における品質や開発手法を一緒に考え議論する場であり、様々な立場の方々からの視点でかなり詳細に課題提起している会でした。
機械学習における課題は、機械学習関連の企業に勤めている人たちの間では、なんとなく解釈されていて、暗黙の了解のように皆共通で感じていることが多くあるのですが、一歩外に出ると、課題はもちろん理解されていないし、機械学習が魔法かのような扱いを受けることが多々あります。
(発注者と受注者の間で巻き起こる論争。。。。)
Twitterなどで、課題提示している人もいますが、大抵は、文章量の少なさや背景知識の差が大きすぎて、マウントをとっているように聞こえることが多く、過去炎上しているものも見受けられました()
今回のイベントでは、そのようなことは一切なく、わかりやすく課題について議論していたので私的感想を含め、レポートを書いてみました。
※技術者目線ではないということだけご了承ください。
各講演内容のサマリー
各講演内容で自分が印象に残ったところをグラレコ形式でさくっとまとめてみました!
ちなみに各講演者の講演スライドはこちら
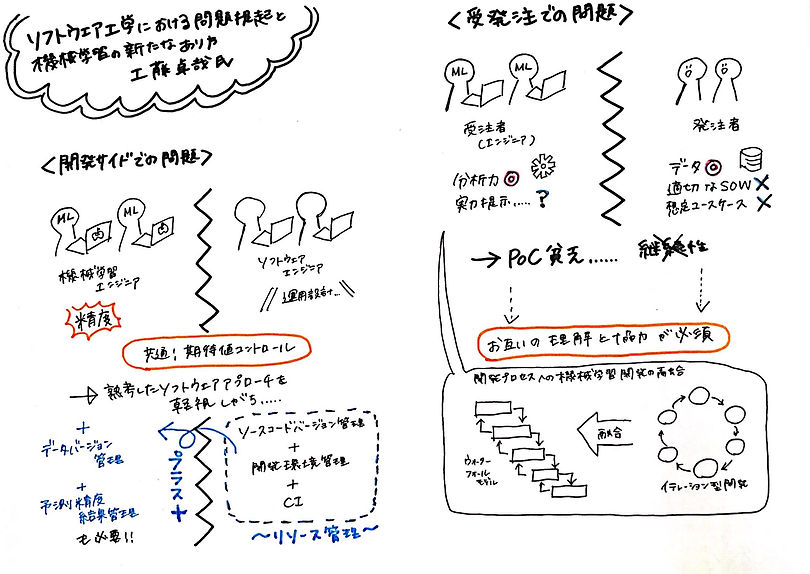
①ソフトウェア工学における問題提起と機械学習の新たなあり方
講演者:工藤卓哉(アクセンチュアUSA Data Science Center of Excellence グローバル統括 / ARISE analytics CSO)
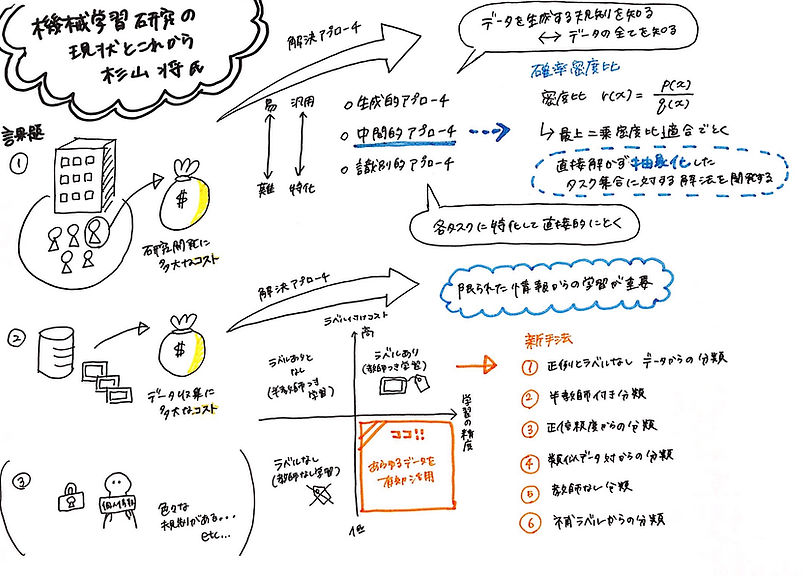
②機械学習研究の現状とこれから
講演者:杉山将(�理化学研究所 革新知能統合研究センター センター長 / 東京大学 大学院新領域創成科学研究科 複雑理工学専攻 教授)
③仕事ではじめる機械学習
講演者:有賀康顕(Cloudera株式会社 フィールドデータサイエンティスト)

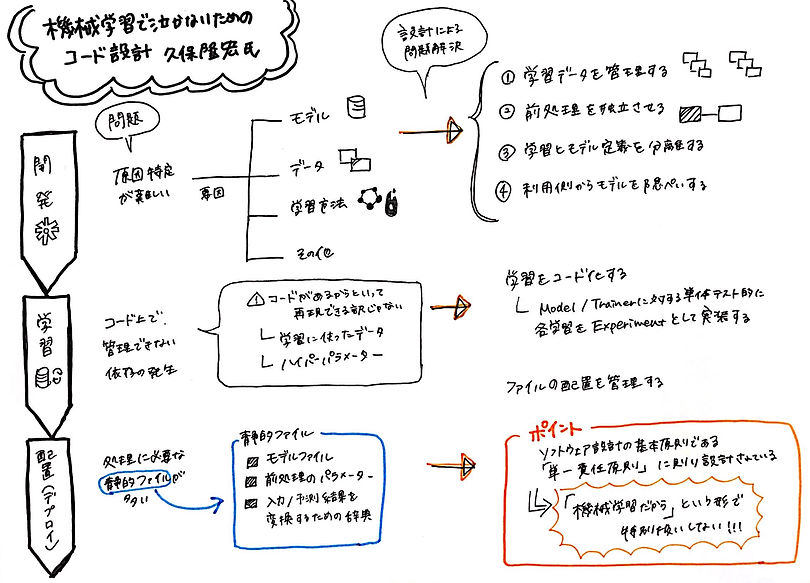
④機械学習で泣かないためのコード設計2018
講演者:久保隆宏(TIS株式会社 戦略技術センター AI技術推進室)
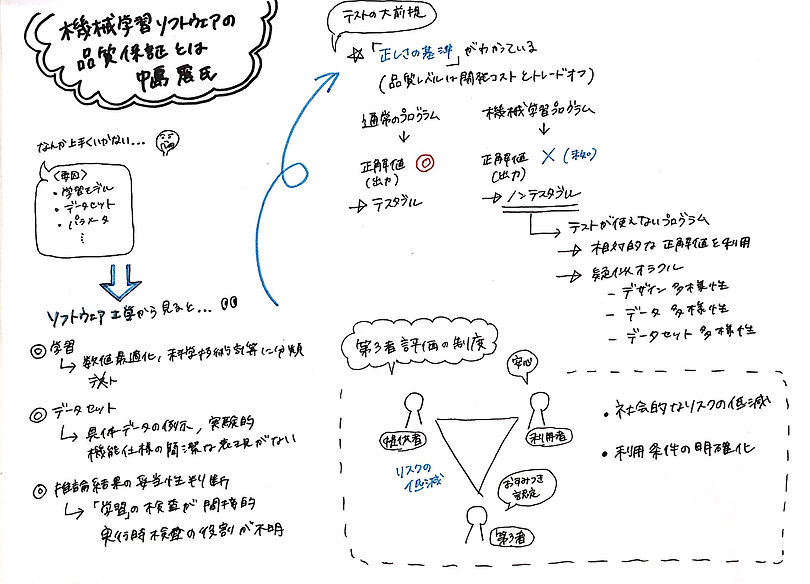
⑤機械学習ソフトウェアの品質保証とは
講演者:中島震(情報・システム研究機構 国立情報学研究所 教授)
⑥機械学習工学への期待
講演者:��青山幹雄(南山大学 理工学部 ソフトウェア工学科 教授)
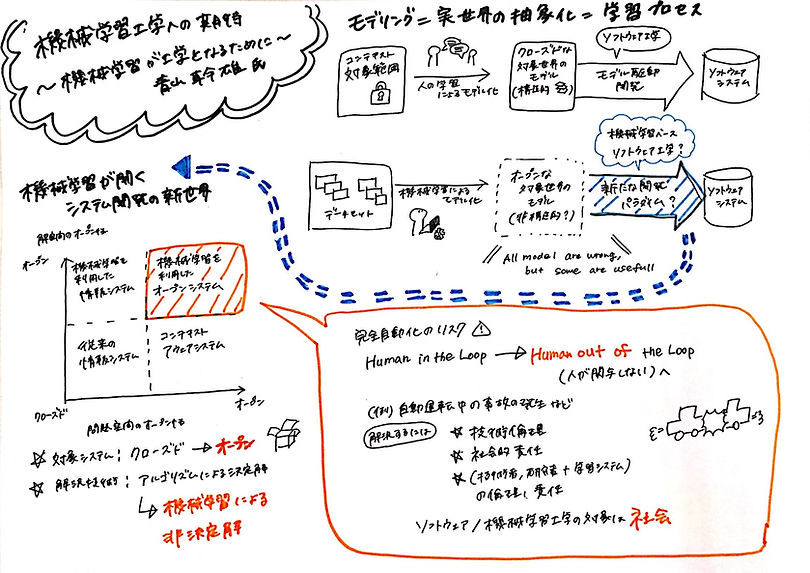
今回イベントで大きく提起された機械学習における課題

この辺りを聞いただけで、「あるある〜!」と思われた方も多いのではないでしょうか?
そうだよね、賛同しますというのが大枠の感想ですが、実際にどういうことがあったとかいう話を含めて述べていきます。
PoC貧乏に陥りがち
どういうことかというと、PoCというお試しのような感じで実証実験みたいなことをディープラーニングや機械学習の業界ではよくやっていて、ちゃんと実力が発揮できるか、本当にその手法でうまくいけるか(精度が出るかとか)の検証をします。
そこで、結果が出て、実用的に運用できそうだ、となれば継続案件に繋がります。
ただ、ここでいうように、PoCってポシャることが多いです。
それで、PoC貧乏と言っているんですが、なぜPoC貧乏に陥ってしまうかというと、発注側にも受注側にも課題があります。
-
想定ユースケースがない。
-
要件定義が難しい。
-
発注側と受注側にリテラシーの差が大きすぎる。
-
達成すべきKPIが握れていなかった。
などなど。
講演でも何度も出てきましたが、基本、不確実性要素が多いので、走り始める段階で仕様はガチッと決まらないことが多いです。そもそもこのシステムを作って何がしたいのか、実際にどうやって実務に取り入れるのかなどの観点が抜け落ちると、精度が良かろうが、残念な結果に収束します。
あとは、そもそもPoCにも行き着かない段階で、有賀さんがおっしゃっていた「データあるある詐欺」は、本当にあるあるです。
異常値ばっかり集めていて正常値がないとか、画像サイズがバラバラ、異常検知したいのに解像度悪すぎて認識できない、全体が必要なのに部分しか写ってないなど。
データあります!と言っても、本当にそのデータ使えますか?というのは多いので、もし、今からデータ収集する方々は、集める前にこういうことがしたいからこういうデータを集めようね、というのを事前に固めた方がいいです。
ソフトウェア開発の基礎的なエンジニアリングアプローチや運用設計などが軽視されがち
私はなんとなく肌感で、通常のWEBサービスに落とす時の必要な要素すら満たさないままGoしそうなことに不安を感じていた時期を思い出して、この話題が出た時に、あ、もしかしてあるあるなのか?と思いました。(笑)
これは総じて、「機械学習だから」という形で特別扱いしない!!!ということを主張することとなるのですが、精度など機械学習における指標を追い求めすぎて、その他の何を持って品質を担保するかとか製品化した後の運用保守をどうやっていくかとかどうやって顧客満足度を上げていくかとかなどの視点が抜け落ちてしまうということです。技術ドリブンな会社だと起こりがちだと思うので意識することがまず大事だなーと思います。
期待値コントロールは必須
先ほどの要件定義が難しいという話と繋がりますが、不確実性要素が高い機械学習ソリューションだからこそ、期待値コントロールは大事です。基本的に、精度100%は厳しい世界ですということすら握れていなければ、結果を提示した際にこじれてPoC貧乏になります。
考えられるリスクなどは事前に共有しておきましょう。。。。
あとは、機械学習で何かできませんか?というレイヤーからPoCまで持っていくのも難しいと思っていて、機械学習で何かできないか?という視点を深める為に、自分でこのような機械学習のリーンキャンバスなどで簡単に考えてみることも個人的には重要かなと思います。
https://www.slideshare.net/nishio/01-68382174
機械学習ソリューションは走り続けないと劣化していく
劣化する、というのは、最初の要件定義がしっかりできていないからなのでは?という質問も当日出ていましたが、そういうことではなく、そもそも入力のデータが変わってしまったとか、レコメンドすることでユーザーの行動自体が変わってしまったなど予測できない事象により、アルゴリズムを常に変化させていかなければならないので、常に監視してサポートしていかなければならない、ということです。
機械学習関連のソリューションは、実装して提供して終了ということはほとんどなく、むしろ運用・保守も重要で、継続して見れる人がいない場合、機械学習ソリューションを取り入れるのはあまりおすすめしません。
また、有賀さんや久保さんのおっしゃる通り、学習データ自体のバージョン管理やモデル自体のリネージも重要になってくると思います。(CometMLみたいな、この辺りのサービス出たらバズりそう(小並感) https://www.comet.ml/ )
原因特定が難しい
精度があまり出ないとか色々問題が生じた時に、なぜ、そういうことが起こってしまったのかの原因を特定するのは、要素が多すぎて難しいということです。私はモデルかデータがおかしいのでは?くらいしかないのかと思っていたので勉強になりました。
久保さん曰く、「機械学習がうまくいかない=モデルの問題と思いがちだが、実際はあらゆる箇所に落とし穴がある。」とのこと。
最後に
「機械学習だから」という形で特別扱いしないという部分は、開発だけでなく、ビジネスサイドにも言えることで、(よく弊社もあることですが、)精度などの技術的要素ばかり追っていて肝心のプロダクトの差別化ってどこでしたっけ?実用化するときになってそれ世間が求めてましたっけ?といったマーケティング視点が抜けているなど技術的要素以外の部分が注意できていないということが起こりがちだと思うので、「機械学習だから」という形で特別扱いしないというのは、全職種の方々に言えることであり、自分も肝に命じていきたいと思いました。
ただ、機械学習工学研究会をはじめ、様々な立場の方々が集い、課題や今後の将来について議論する機会があるというのは素晴らしいことであり、どんどん改善・解決して、この分野が成長・発展していくのが楽しみです。